Projet DATA : Scraping & Visualisation de données
Extraction de données depuis Autotrader, stockage en base MySQL, nettoyage avec Pandas et visualisations avec Seaborn. Un projet complet de traitement de données réalisé en équipe.
3/2/20251 min read
Scraping & Visualisation de données e-commerce
Dans le cadre du cours de Data à l’ECE Paris, ce projet vise à mettre en œuvre un pipeline complet d’exploitation de données réelles issues du site Autotrader. Nous avons développé un scraper pour extraire les informations produits, structuré une base de données MySQL, puis nettoyé les données avec Pandas avant de les analyser visuellement avec Matplotlib et Seaborn. Ce projet nous a permis de combiner des compétences techniques en Python, SQL et data visualisation, tout en travaillant efficacement en équipe.
🎯 Objectifs du Projet
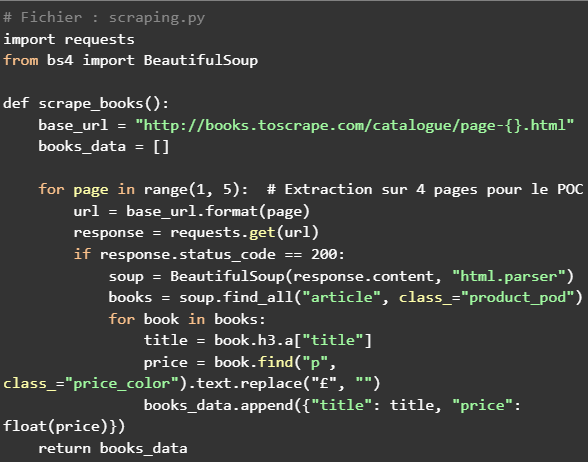
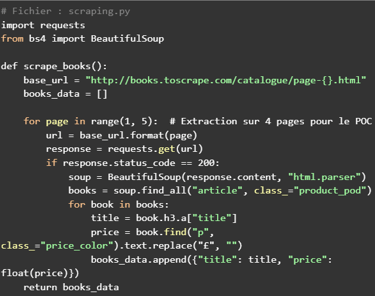
✅ Scraper un site e-commerce réel (Autotrader) pour collecter des informations produits (titres, prix, catégories).
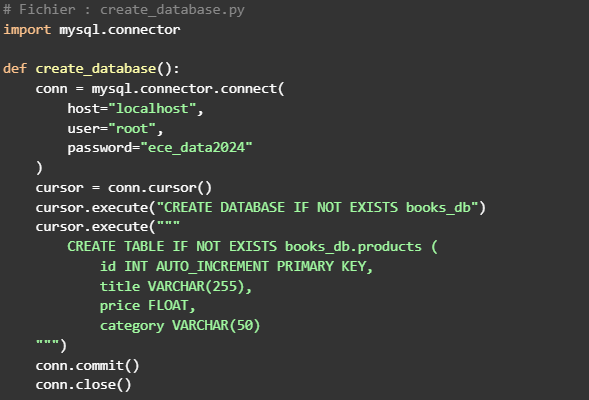
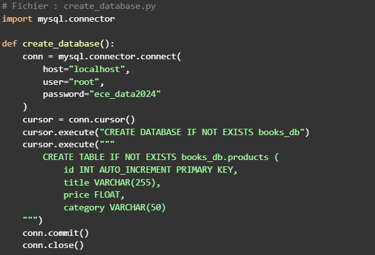
✅ Stocker les données dans une base MySQL structurée avec contraintes.
✅ Nettoyer les données avec Pandas pour garantir leur qualité et cohérence.
✅ Analyser et représenter les données avec Matplotlib et Seaborn.
⚙️ Pipeline de traitement
🔗 Scraping avec requests & BeautifulSoup (HTML simple, pas de blocage).
🗃️ Intégration MySQL : création de tables, insertion automatisée.
🧹 Nettoyage intelligent : gestion des NaN, normalisation des catégories, typage strict.
📊 Visualisations : distribution des prix, produits par catégorie, etc.
🚀 Compétences mobilisées
Manipulation de données réelles
Automatisation d’un pipeline de traitement
Collaboration technique en équipe
Présentation structurée des résultats
💡 Leçons retenues
Importance de la robustesse du scraping (site HTML changeant)
Qualité des données = qualité des insights
La visualisation permet de donner du sens aux chiffres
Localisation
ECE Paris, 37 Quai de Grenelle 75015, Paris FR